





















Business
Took responsible approach to train our AI models: Ap
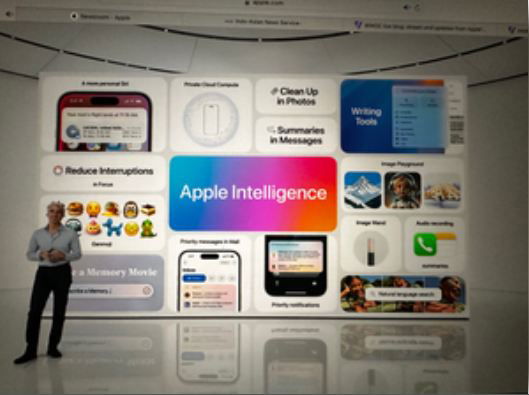

1 hour ago
After row over childlike sex dolls at Shein, now Hindus upset at Shein for Lord Ganesh blanket

2 hours ago
Kangana Ranaut left speechless by the beauty, culture & authenticity of Gujarat

2 hours ago
Shakti Mohan pens heartfelt b’day note for sister Neeti: You are my life’s biggest blessing

2 hours ago
Arjun Rampal, Akshaye Khanna spell terror in supercharged ‘Dhurandhar’ trailer

2 hours ago
Sonali Bendre recalls the backstage chaos on the set of 'Pati Patni Aur Panga'

2 hours ago
Shraddha Kapoor has a pertinent question for photo editors

2 hours ago
Huma Qureshi on her bond with success, failure: I'm able to enjoy my work

2 hours ago
Akshay Kumar & Tiger Shroff flaunt picture perfect abs during their Juhu Beach edition of 'Ocean’s 9'

2 hours ago
Kerala achieves 96 pc enumeration in SIR; concerns remain over coverage, timing

2 hours ago
J&K Police unearth Jaish's link with banned Kashmiri women terror group Dukhtaran-e-Millat

2 hours ago
SC issues notice on PIL seeking probe into alleged bank fraud by Anil Ambani-led RCOM

2 hours ago
If elections are held again using ballot papers, results will be completely opposite: Robert Vadra on Bihar polls

2 hours ago
Shashi Tharoor welcomes PM Modi's call for post-colonial mindset, cultural confidence